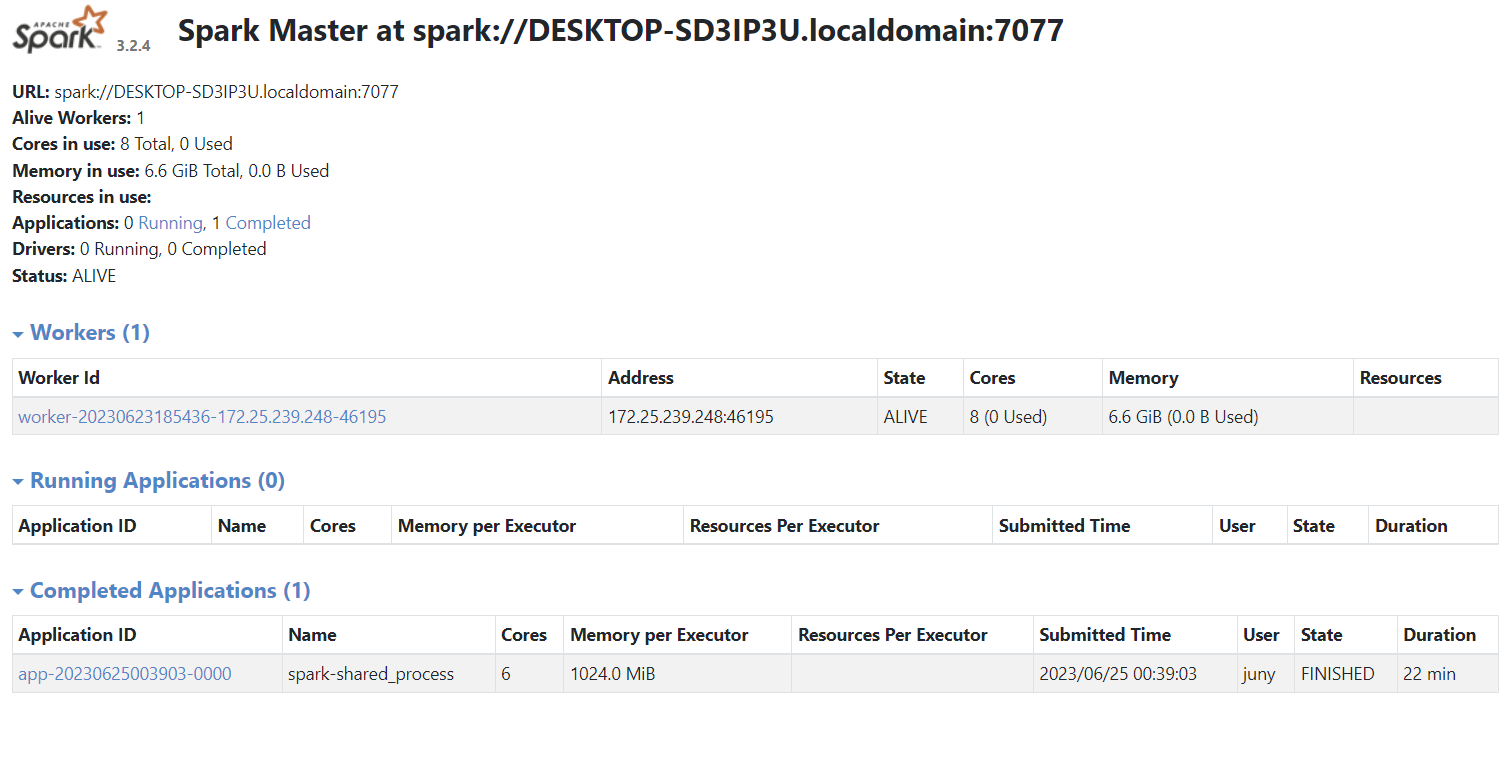
PySpark
Configuring PySpark Job Cluster
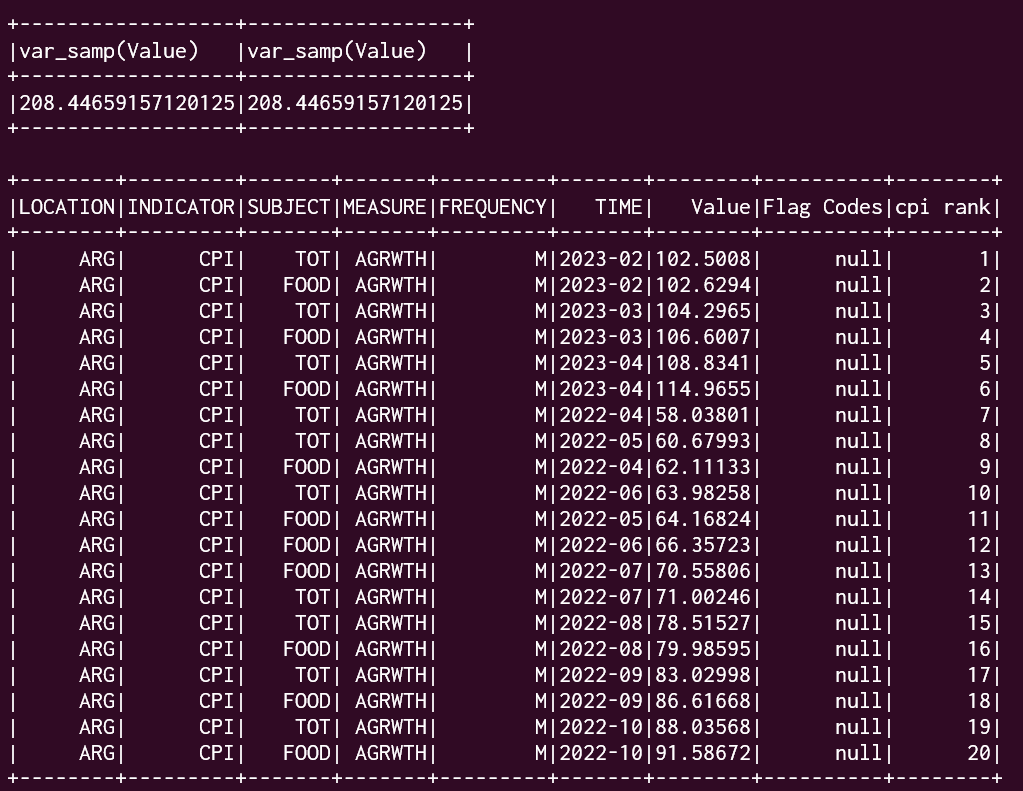
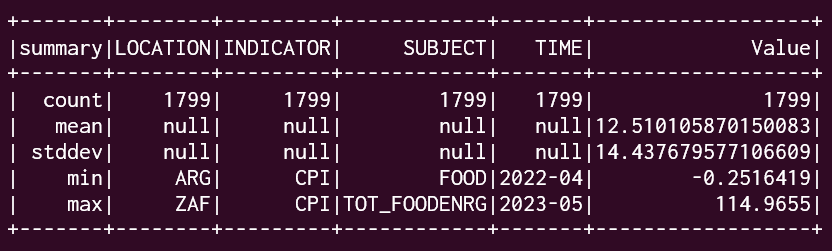
from Submitting job to refine data ,
Worked with window and statistic function
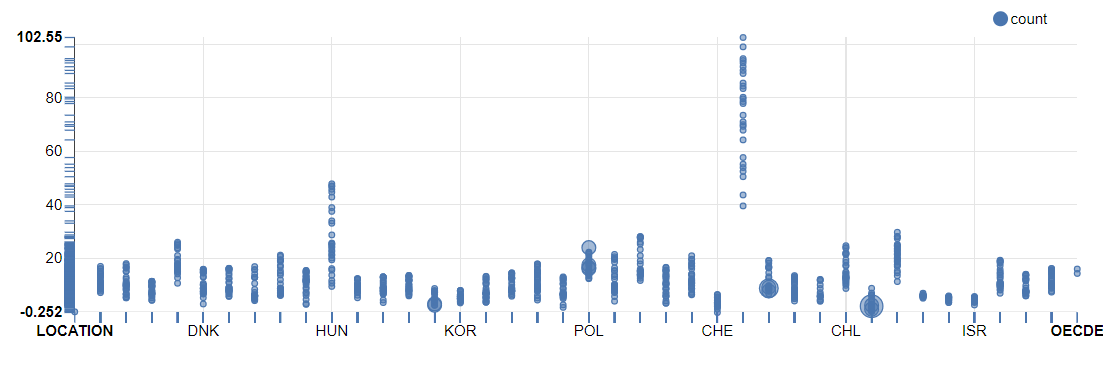
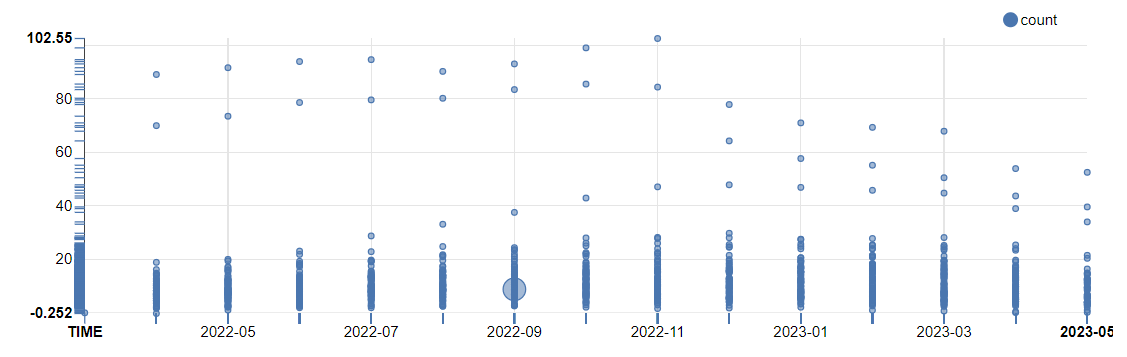
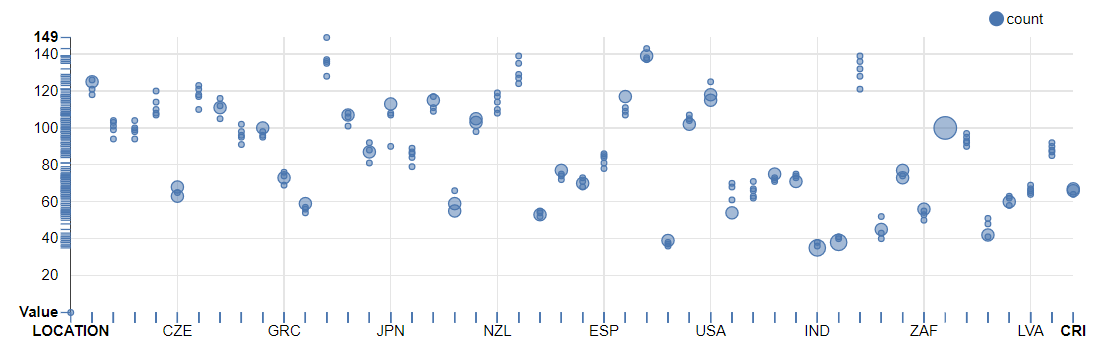
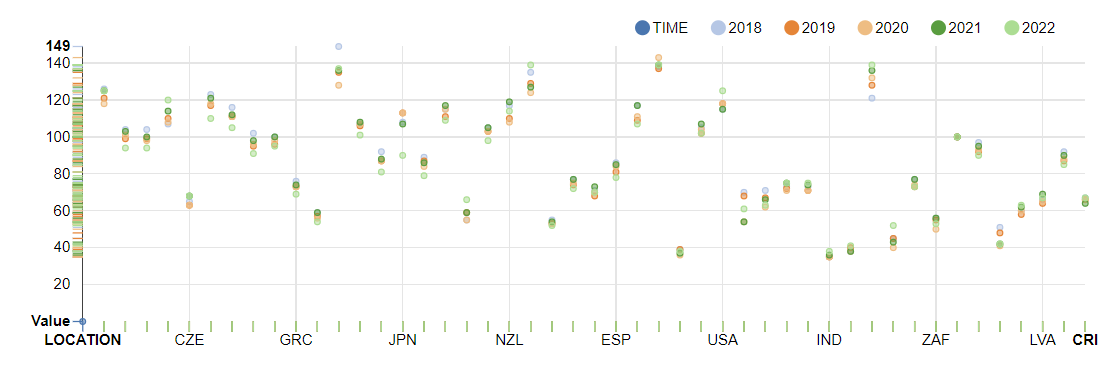
At last, It worked with World Economic Indices to visualize
for Time Series Data in Zeppelin
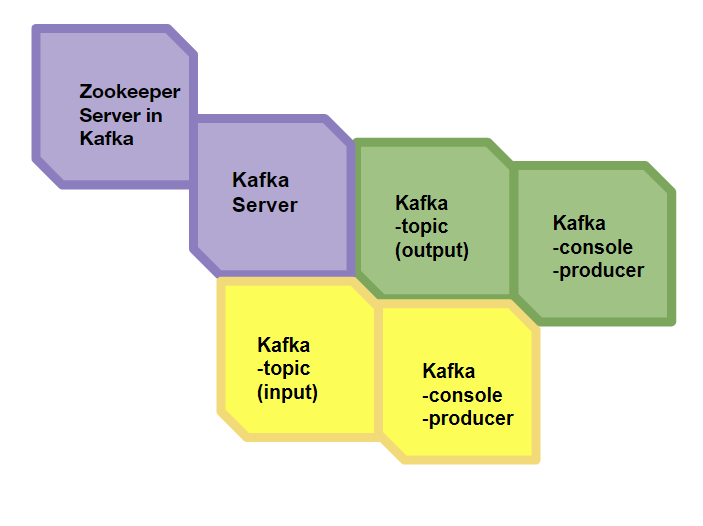
Real - Time Streaming
with Kafka
Updating World News Stream
and, Building Recommendation System
△ Logic for Implementation
State :
Made in dataframe to build recommendation modeling
And, Ready to build Java consumer to connect with jdbc
Further, Testing elastic search
Flink will be last task to reduce and map with Geology data (Through Jar file or Zeppelin flink)